The basic package explicitly assumes that a large number of electronic modules are used in connection with each other. The present electronic manufacturing technology enables to place those modules on a 2-dimensional surface (in several layers) as described in section Module grouping. When considering the connectivity of the modules, from the point of view of wiring, signal timing, transmission time, etc. the topological position can be important, so the package enables to place the modules at well-defined positions and also provides topology-based communication elements between the modules. During the communication this information is actively used to make message routing more effective.
Today, on a Si die a lot of modules are placed, arranged in a rectangular form. Usually they are the same "intellectual property", simply cloned to different places and being segregated from each other. As shown, the GridPoint objects have XP and YP positions formed from the X and Y coordinates. All these are proper physical addresses.
The GridPoint class simply introduces the concept that the electronic modules have topological position (and so: neighbors and distances from each other) and they can maintain some kind of relationship with the fellow gridpoints. However, GridPoint is a math-only class.
The AbstractTopology is also a math-only class: given that the modules are technologically arranged according to a 2-dimensional grid, the grid points points are arranged into also a 2-dimensional grid and they can be addressed through using their X and Y coordinates. The grid points (having identical internal structure) may be more conveniently addressed with a simple sequence number (i.e. they are arranged in a vector, and they can be addressed through their index).
For the GridPoint objects arranged in a way like this, a distance can also be interpreted. The zero distance means the module itself. The distance is one, if the modules have a common boundary, and the distance is two if they have a common neighbor.
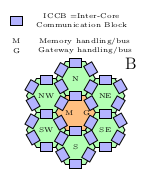
The native form of grouping the modules into a higher-level unit is clustering them. The hexagonal arrangement enables to surround a module with 6 other modules, see the "flowers" on the figure Fig_Hexagona2. These 6 modules are first-order neighbors (or internal members of the cluster). Normally, in the case of complete clusters, see below, only the first order members belong to the cluster (of course in addition to the zeroth-order member, the cluster head), but in emergency cases (see the phantom clusters below) some second order members are also be attached to the cluster.
As mentioned, a GridPoint can be described by its rectangular coordinates (X,Y), by the topological position coordinates (XP,YP) and they can be described also by a simple sequence number N. The clustering provides one more option: the gridpoints can be logically addressed through their corresponding cluster address (C,M), where C is the sequence number of the cluster and M describes the member relative to the cluster head. All the mentioned module IDs are unique and can properly identify the module: they are all referring to the same physical unit.
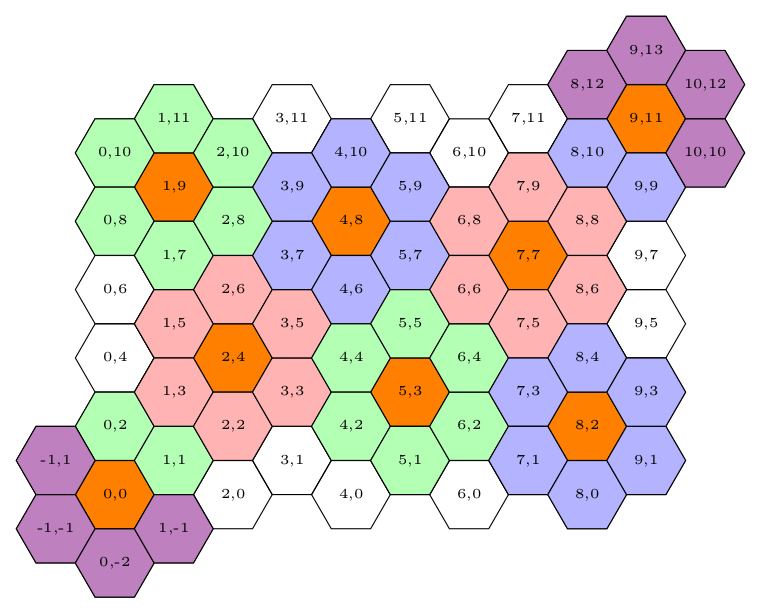
As shown in the figure, the clusters inside the square grid (i.e. when all logical grid points of a cluster can be mapped to physical modules) are complete clusters: the head and all members are physically present (i.e. all they can be mapped to physical modules). At the edges of the square grid, some clusters are only partly present. These incomplete clusters can map their cluster head to a physical module, but not all of their members correspond to a physical module: the hexagons corresponding to the missing modules are filled with light violet. There are also some phantom clusters: the cluster head cannot be mapped to a physical module, but at least one of its members can. These hexagons have white background.
Here the basic elements comprised in the package are described. The elements, signals, etc. primarily named and used as usual in the electronics. In the other two packages the same basic elements are used for subclassing the basic modules of those blocks, under a different name. In this booklet only the base functionality and operation is described. The other booklets are intended to be self-contained, but the interested reader may want to know, how those facilities are established in the deeper layers.
One of the focal points is to organize the communication differently. Another point is to provide flexibility (morphing the architecture), in addition to the conventional way of operation. In the package the inter-module communication is implemented as background activity. The foreground activity is cut into two mutually exclusive parts: the modules either work in a conventional way or they are morphing. Since morphing may involve other scGridPoint modules, those operation can only be carried out with the assistance of the scProcessor, that is reponsible for the operation of the system.
The scGridPoint is an anchestor class of electronic modules (sc_core::sc_module [2]) with communication facilities. It knows its topological position (it is a GridPoint), can communicate autonomously and independently from its payload activity. It is a good anchestor for both cooperating (nearly) conventional cores or specialized artificial neurons (neurers).
The large number of electronic modules must be handled by central facilities. If the gridpoint modules must organize the joint work in their (otherwise) payload time, the payload efficiency strongly degrades as the number of modules grow. Because of this, an scGridPoint has a top layer (for the foreground activities, like computations) and a bottom layer (for the background activities, like operating the communication (sending, receiving and forwarding messages). The top layer can work in two regimes. In the conventional regime the module works in a conventional way (like the core processes conventional instructions) and in the meta-regime it executes meta-instructions (configuration). Both kinds of operations are built up from elementary steps (in the conventional regime: machine instructions, in the meta regime: elementary configuration step, after which processing can continue in a reasonable way). In both regimes all resources are utilized, so an elementary action can be either conventional or meta action, but only one at a time, and the action must be completed before the next action can be taken.
The operation of the bottom layer is only loosely coupled to that of the upper layer. The upper layer uses the bottom layer "as a service": can send and receive messages to/from the other gridpoints, with as little overhead as possible: the load of synchronization, routing, delivering is on the bottom layer.
The topology introduced above enables the members of the cluster to reach each other either directly or through the cluster head as a proxy: the common boundaries enable to prepare dual-access elements, (communication channels) in this way implementing a direct way of communication (i.e. without the need of any global bus, see section The inter-gridpoint communication block). The communication is a native feature of the grid points: they communicate in the background (when needed), independently of the foreground activity the gridpoint makes.
From communication point of view, the best idea is to consider that the modules have (logically) hexagonal shape, they have neighbors and through the common boundaries they can exchange data using a mechanism very similar to those used inside the cores. This "gridpoint-to-gridpoint bus" (the lowest level in the hierarchy) is actually not really a bus. Rather, it is a dedicated point-to-point connection, without latency time and contention, i.e. a very high speed transfer between the neighboring cores.
With the technical development, the processing time of computing by procssing units is continuosly getting shorter than transferring the data to the place of processing. Because of this, the processing unit if blocked by the missing data. To overcome this very pure utilization of the processing unit, hardware threads scHThread has been introduced. The idea is taken from the SW idea of threads, but the HThreads have also HW attributes, such as internal registers, state flags, cache registers, and so on.
The computing is based on scHThread units. When a computing thread (represented by an scHThread) is ready to run, it sends a request to its processor core. If that request is not busy, the scHThread "owns" it for the time it needs it: the other scHThread units attached to the same scGridPoint, will be able to run only if the current scHThread released the computing resource. Given that the scHThread processes spend most of their time with waiting for data or for each other, this method enables to maximize utilization of the computing resource.
The operation on the scHThread is completely transparent for the programmer. The programmer simply starts a SW process on a scHThread, and the process runs as the current HW situation enables it.
Notice that
This feature can be used to implement a special way of inter-cluster communication. The communication channels are built on all boundaries where on both sides a GridPoint is present. This serves primarily inter-cluster communication. However, the gridpoints having a common boundary with the members of the cluster may use that cluster member as a proxy; i.e they can be considered as an "external member" of the cluster. The "external member" GridPoint can be addressed by coordinates (C,M,P), where C is the number of the cluster, P is the member used as a proxy, and M is the "external member" described in the same way as a member: relative to P.
Even, the morphing of the architecture enables to re-group some GridPoint objects from one cluster to another, provided that the primary member of the donor cluster is a secondary member of the acceptor cluster. In this way quite large clusters (comprising altogether 1+6+12 members) can be created. Another useful possibility is to group the usable cluster members of a faulty cluster head to another cluster, in this way losing only one GridPoint, rather than a whole cluster.
The next higher order unit is scProcessor, the scGridPoint modules belong to. The processor does not make calculations. Instead, it organizes the job, and oversees the operation of its cores. It handle the resources, including borrowing them for collective operations.
The scGridPoint modules represent the bottom layer of the subclassed modules such the different processors (including also neurers) and one of their task is to route the messages to the right place autonomously, using only the information compressed in the message and without the help of the top layer.
Notice that the modules with distance two can be reached using the common neighbor as a proxy. This feature is independent from whether the gridpoints belong to the same cluster.
The hierarchic addressing enables to implement the purely address-based routing easily. However, as the direct message transfer is implemented independently from the cluster architecture (i.e. a direct connection channel between scGridPoint modules belonging to different clusters also exists), an additional method, the "forced direct" transfer is also implemented. It means, that if the transfer can be solved without using inter-cluster bus (say, the source and the destination belong to two different clusters, but are first or second orer neighbors), the direct transfer is preferred. This complicates routing, but enables speedier message transfer and considerably increases the capabilities of the scGridPoint (and the subclasses derived from it).
The details of the routing method are given in scGridPoint::RouteMessage. The message source (and scGridPoint) assembles the message and calls this function; the rest is for the underlying architecture. This method enables QT handling, including "remote procedure calls" and "in-memory calculations".
The clusters between each other can communicate using the scClusterBus bus. Every single cluster head is connected to the bus, plus the rest of the components. The formers have natively have The cluster head has natively its ClusterAddress_t address, the other are subclassed from scGridPoint, i.e. they have all the functionality of an scGridPoint, plus some extra functionality. The figure in section The scClusterBus scheme shows how tose elements are connected together. Notice that here the communication between components is natively belonging to the components: the communicating modules address what they want and the rest is the task of the bus and the partners. The control and data synchronization happens at HW level, rather than OS level.
The idea is that the cooperation data and control information transfer should be kept at the lowest level and as local as possible. Especially in large (meaning either large number and/or large physical size) systems the scalability is rather wrong as the size of the system increases. The conventional technology requires to use some kind of granularity of singleton units (say imagine cores, processors, cards, racks, etc.), and the units at different levels are connected via a singleton high-performance bus. Here a simple hierarchic bus system model is proposed that is inherently able to separate the bus traffic into 'local' and 'remote' traffic, at several levels.
Both scIGPCB and scClusterBus are part of the hierarchic bus system. While for in-cluster communication a special direct connection (the scIGPCB modules, i.e. not a bus in the conventional sense) is used, scClusterBus is a conventional bus: it delivers messages from one cluster to another. In technical sense, only the cluster heads are connected to the bus, the non-head points can reach each other via sending their messages to The cluster head.
The cluster heads comprise a communication gateway element, that enables them to send the messages to another cluster. Similarly, the scProcessor contains the next level gateway (not implemented at the present stage of development) to connect the processors, and similar gateways are present at the higher levels of hierachy.
This is the description of a simple abstract bus model, for a higher performance modeling, especially for EMPA comprising scGridPoint modules. The modeling is done at Transaction Level, and is based on cycle-based synchronization. The different components of the system are connected to a special bus as shown on the figure below.
The modules connected to the bus must 'own' the bus for the time of their data transfer. The scClusterBusArbiter is contacted by the modules via issueing a ClusterBusRequest The conventional principle of sharing the scClusterBus is kept: via the scClusterBusArbiter arbiter unit, a master can request the only available bus and its access can be granted, in different forms. Any of the modules are able to send message to any other. To do so, all modules connected to the bus have both master and slave interfaces, see scClusterBusMaster_blocking and scClusterBusMemorySlow. (Yes, the memories can directly send messages to each other: think about cache operation and gls{I/O} buffering)
All modules connected to the bus have their unique ClusterAddress_t address and as masters, they have also their unique bus access priority. For details see the corresponding sources. This is just the technical way of connecting the modules, allowing them to transfer data from one scGrisPoint to another; it should not be mismatched with the the cooperation of the modules, described in section The cooperation.
Given the limited capacity of the developer, in this early phase of development at some places the bus operation is only imitated (i.e. momentaily replaced with a direct access plus timing delay). This does not affect basically the viability and feasibilty of the operating regime, however the exact timing may be slightly different from the simulated one.
The special arrangement of the computing elements enable to use "local" and "distance" traffic in the computing elements.
Along the common boundaries special electronic blocks scIGPCB are prepared; always in pairs, originating and ending in the modules at the two sides of the boundary, and making a direct connection in both directions. This simple "bus" (implemented as a FIFO) is wired directly to the other party, the sending modules writes directly to the party's FIFO, where the receiver puts the received message into latch registers utils finally processed.
There are as many scIGPCB modules in as scGridPoint, as many common boundaries of the representing hexagon with some other hexagon. (there is no connection with the "violet" (phantom) members, but there is with the "white" (external) members). There is no competition, no arbitration, no synchronization need, no setup time. The neighbor's buffer is simply part of the module (if it is represented as a FIFO, it is read by the owner module and written by the corresponding neighbor).
The sender assembles the message (including the response address) and initiates the transfer, but after that it shall not wait, the transfer is carried out in the background. The sender can, but should not, wait until the transfer is complete. Sending more messages to the same neighbor is blocked until the transfer completes, but sending messages to other neighbors does not interfere with sending the message.
The sending scIGPCB notifies its owner scGridPoint when the transfer is done and puts the received message in another FIFO (in the scGridPoint).
They scIGPCB submodules serve as a special buffer during the communication among the scGridPoint modules. An scGridPoint sends and receives an scIGPMessage to/from its party on the other side of the boundary autonomously, without needing external control and any additional action from the two modules, it does not contribute to the non-payload activity. The receiving scIGPCB stores the message in a buffer, and parses it: the scIGPMessage is self-contained, i.e. the scIGPCB can completely process the message. Depending on the message type, the scIGPCB can copy register-like contents to the corresponding latches of the scGridPoint, or forward the message as a proxy to another neighbor, or to forward it (through it own cluster head) to the special cluster bus, request memory contents, or the same traffic in the opposite direction. The scGridPoint (still in the background) processes the messages in the FIFO one-by-one and puts the relevant contents in latches, where it is immediately available for the foreground processing when needed.
The important principle that is followed: the modules can send messages though their own scIGPCB when they feel to do so, and the other party reads the message from its own latches when it needs to do so (if the message is not present, it must wait, but no other synchronization is required).
During fabrication, the modules are placed in a 2-dimensional structure, i.e. they have natively X and Y coordinates and they can easily be arranged to form a one-dimensional vector, i.e. they can also have natively a unique sequence number (it is arranged column-wise). The grid points (scGridPoint units) are technologically arranged (and also by technologically: the even rows/columns are shifted by a half grid position). That is, a module can be referred to by a single index (scProcessor::ByID_Get(int ID)), a pair of indices (scProcessor::ByIndex_Get(int X,int Y)), and a pair of coordinates (scProcessor::ByPosition_Get(int XPos,int YPos)); they all refer to the same physical module.
This special (CNN-like arrangement enables us to consider the rectangular grid (logically) as a hexagonal grid. We can also interpret different neighborship relations. The first order neighbors have a common boundary, the second order neighbors have a common neighbor. In order to avoid half numbers, in direction Y the numbers are increasing by two rather than one (that is, in direction Y the position and the index differ by a factor of two). The modules have a common boundary with all their immediate neighbors and can be addressed by using relative coordinates; for example, neighbor NE means the neighbor module of the actual point in direction north-east.
Also, the modules are organized to form functional clusters as shown in Figure Fig_HexagonalCluster. The central module is called the cluster head, the others are the cluster members. The position of the individual modules can be described with their relative position to their immediate neighbor (and maybe second neighbor), they have a special logical address. In this way, a module may have different valid relative addresses, providing the advantage of having different paths when a message needs to reach them during routing.
As shown in Figure Fig_Hexagona2 (the coordinates X and Y correspond to that of the rectangular grid). The rectangular grid is described by an AbstractTopology, where a vector, and a two-dimensional vector stores the address of the GridPoint objects. Also, the cluster heads are stored in a special vector. Given those storage methods, the GridPoint objects can be reached through different addressing methods, although the different addressing methods refer to the same physical module.
Notice that the common boundaries enable a special method of communication, direct wiring, which is the lowest level of the Hierarchic communication. The blueish boxes are a special two-way communication unit (scIGPCB: the inter-gridpoint communication block), which enables a register-like communication between the direct neighbors.
The arrangement provides one more advantage. The direct wired scIGPCB blocks enable a (because of the direct wiring, economic) way of using proxy cores for messages. Any of the modules can serve as a proxy communication station for its neigbors. The special addressing mode Module's hierarchic logical addressing enables to provide also a proxy address (it must be a first-order neighbor of the real target module), enabling to attach (denied or orphaned) modules to a "foreign" module.
From addressing point of view, the head is a cluster member with in-cluster index ClusterNeighbor::cm_Head (zero) and of course has ClusterStatus::cs_Head. From architectural point of view, the cluster head is somewhat different from the simple members: they are 'fat' in the sense that they have two further elements. They have access to the inter-cluster bus (scClusterBus), which represents the next level of the Hierarchic communication. The cluster heads (any only the heads) have access (wiring) to the memory system (M) and they serve as a gateway (G) to the higher-level Hierarchic communication, the inter-processor bus (presently not implemented). The rest of cluster members is not wired to those external world; they must request their cluster head to proxy that functionality.
Of course, a rectangular area cannot be covered with hexagonals without difficulties. As Figure Fig_Hexagona2 displays, there are incomplete clusters (where the cluster head exists but some of its first-order members are not implemented) and there are phantom clusters with orphan members: the member is physically implemented, but has no physical cluster head module (just a logical core: a phantom). The orphan cores are joined to one of the neighboring clusters during fabrication: they simply have a predefined proxy, so they can be used as a full-value scGridPoint; the only difference that in their address the ClusterAddress_t::Proxy field is not zero.
One of the key factors of scalability of computer networks is the sub-networking, i.e. communicating nodes are organized in a way that the communication takes place, as much as possible, within the subnetwork and only the part that targets other sub-network uses the higher level buses. The other key factor is that "the communication-to-computation ratio" is not much worse for the higher-level communication than that for the communication within the sub-network: the networking minimizes the number of "hops" needed to reach the destination.
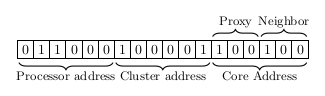
The cluster address is composed akin to the subnetworks of the computer networks. A cluster is composed of 1+6 gridpoints, leaving space for a "broadcast" type message, too.
The address of an scGridPoint (otherwise GridPoint #2) is given throughout this booklet as
where {Xpos,Ypos} are the topological position of the GridPoint and (Cluster.Member:Proxy) are the logical (cluster) address. The {Xpos,Ypos} coordinates enable to locate the scGridPoint for the user on Figure Fig_Hexagona2, and (Cluster.Member:Proxy) form enables the routing to deliver the message to its destination. Notice that proxy is not used in most of the cases; in such cases the default ':Proxy' is not displayed.
That is: {0,0} is the head of cluster 7; {0,4} is the north neighbor of the north member of cluster 7. Notice that some nodes have neighbors from a different cluster, so they might have two valid addresses: one with proxy using a foreign cluster head and one as ordinary element with their own proxy. This facility provides redumdanca and extraordinary facilitities on traffic organization. Say,
are also avalid access path to reach node
This addressing gives way to Hierarchic communication.
Given that the central elements (with orange color) have physically distinguished role, the usual way of addressing is to provide The cluster head in the address.
The mentioned physical addresses can be used referring to an element of a vector or a matrix of the modules, but they must somehow be mapped to the network connecting them, also needing additional protocols.
Similarly to computer networking, any of the native IDs can be used to address the scGridPoint modules. The logical addressing is based on the ClusterAddress_t address that enables the set of the scGridPoint modules to deliver the messages to their destination in the bottom layer of the scGridPoint modules. In the present version only one scProcessor is assumed and used, but the addressing can be trivially extended to higher order modules (such as cards, racks, etc.) The only requirement is to distinguish one of the cluster heads, processors, etc. that has access to the higher level communication bus, and the message is automagically forwarded to any scGridPoint in the system. Presently ClusterAddress_t is assumed to have 32 bits.
 1.8.17
1.8.17 
